
正则基础语法和修饰符
这里是正则基础
普通
abc
- 写啥匹配啥

|
- 表示
或,比如 a|b 就是 a 或 b

[]
- 从里面选一个,相当于一堆或,a|c
- 这里匹配了2次,不同批次匹配用不同颜色表示
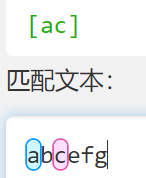
- [abc] == a|b|c
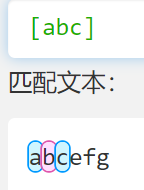
- 连字符 - 选择
ASCII码范围


\
- 转义,用法同C语言格式化字符串的转义
\d表示数字\w表示单词\s表示空格\n表示换行\r表示回车- 字母大写表示
非,比如\D表示匹配非数字
为什么要转义:比如你的 [ 号,你的 [] 语法要用到,并且缺一半报错,让他不要表示语法就转义
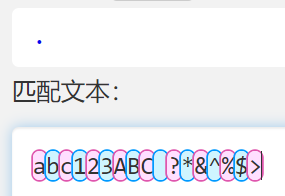
.
- 点号 . 表示匹配任意一个字符
定位
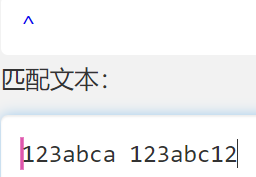
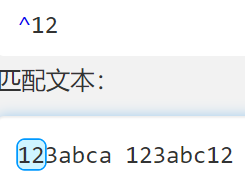
^
- 匹配开头
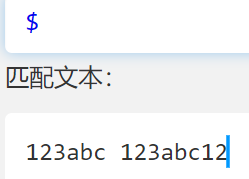
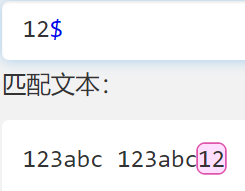
$
- 匹配结尾
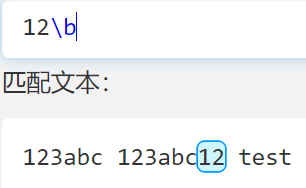
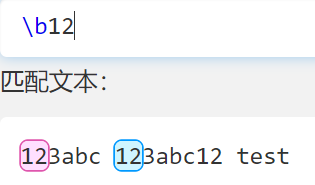
\b
- 表示匹配单词(连续的 abcABC123 )边界
- \B大写表示除了这个以外

限定
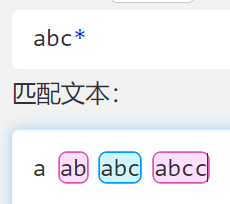
*
- 对前面的东西表示随便匹配(下图表示 ab 加上可有可无的字符 c )
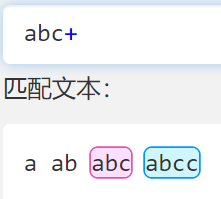
+
- 对前面的东西表示至少一个(下图表示 ab 加上至少一个 c )
?
- 对前面的东西表示是否存在(下图表示 ab 但只能加上一个 c )

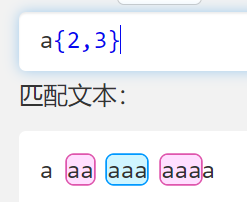
{}
- 用法 {n} 、 {n,} 、 {n,m}
- 对前面的东西指定个数, n 是最少几个, m 是最多几个


选择
()
- 表示打包成一组进行操作
- 比如之前的 abc+ 的加号只对 c 起作用, (abc)+ 的加号就对 abc 整个起作用了
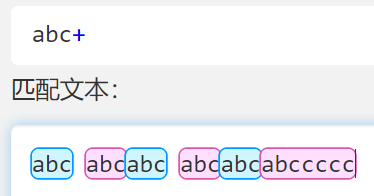
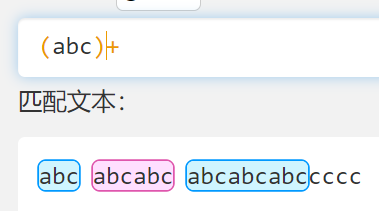
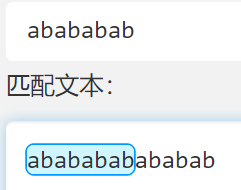
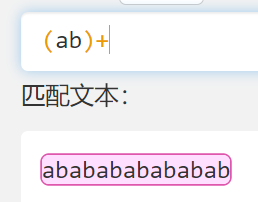
- 匹配多个 ab
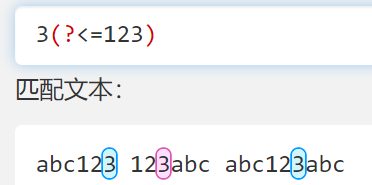
(?=)和(?<=)
- 正向预查,匹配一个边界(查了但不用)
- 下图是查找 123 的前边界
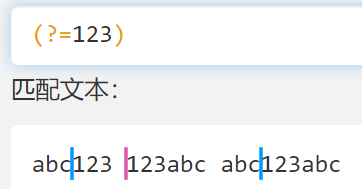
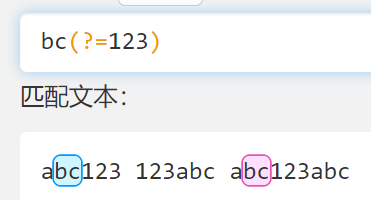
- 利用这个边界进行匹配
- bc 后面没有这个边界就不匹配,一般用来找xxx前面的东西
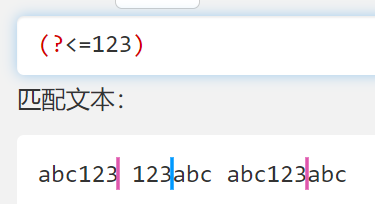
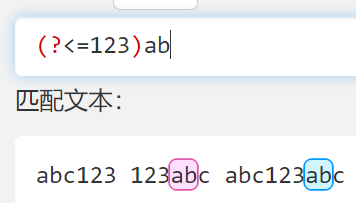
(?<=)效果也差不多,一般用来找xxx后面的东西- 本质上就是确定一个边界
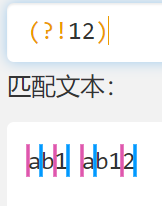
(?!)和(?<!)
- 反向预查,找出前面或后面不是xxx的东西
- 下图如果是 12 ,那就把 12 的 1 前面这条边界砍了,就匹配不到了

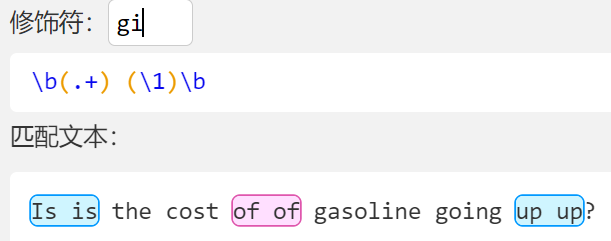
反向引用
- 使用 \1 获取第一个匹配项, \2 获取第二个, \3 获取第三个,以此类推
- 下图演示利用第一个匹配项匹配第二个实现单词查重
正则修饰符
i
- ignore - 不区分大小写
g
- global - 全局匹配,查找所有匹配项
m
- multi line - 多行匹配,使边界字符 ^ 和 $ 匹配每一行的开头和结尾,而不是整个字符串的开头和结尾。
s
- 特殊字符圆点 . 中包含换行符 \n
- 默认情况下的圆点
.是匹配除换行符 \n 之外的任何字符,加上 s 修饰符之后, 点好 . 中包含换行符 \n 。
上述修饰符可混合使用。
#RegExp(1)#正则表达式(1)文章作者:xChenNing
文章链接:http://localhost:8090/archives/zheng-ze-ji-chu-yu-fa-he-xiu-shi-fu
版权声明:本博客所有文章除特别声明外,均采用CC BY-NC-SA 4.0 许可协议,转载请注明出处!
评论